
Ship reliable LLM Products
Ship reliable LLM Products
From evaluation to prompt management, Literal AI streamlines the development of LLM applications.
Trusted by





Trusted by
Trusted by
Trusted by
The problem
PoCs are simple, building production-grade AI products is hard.
Vibe checking prompts only brings you so far
Engineering, Product and SMEs collaboration flow is scattered all over the place
Uncertainty in the iteration process makes it slow
Prompt Regressions
LLM Switching Cost
Dataset Cold Start
Multi-Step Debugging
Data Drift
The problem
PoCs are simple, building production-grade AI products is hard.
Vibe checking prompts only brings you so far
Engineering, Product and SMEs collaboration flow is scattered all over the place
Uncertainty in the iteration process makes it slow
Prompt Regressions
LLM Switching Cost
Dataset Cold Start
Multi-Step Debugging
Data Drift
The problem
PoCs are simple, building production-grade AI products is hard.
Vibe checking prompts only brings you so far
Engineering, Product and SMEs collaboration flow is scattered all over the place
Uncertainty in the iteration process makes it slow
The problem
PoCs are simple, building production-grade AI products is hard.
Vibe checking prompts only brings you so far
Engineering, Product and SMEs collaboration flow is scattered all over the place
Uncertainty in the iteration process makes it slow
Prompt Regressions
LLM Switching Cost
Dataset Cold Start
Multi-Step Debugging
Data Drift
Tailored for the entire
AI development lifecycle
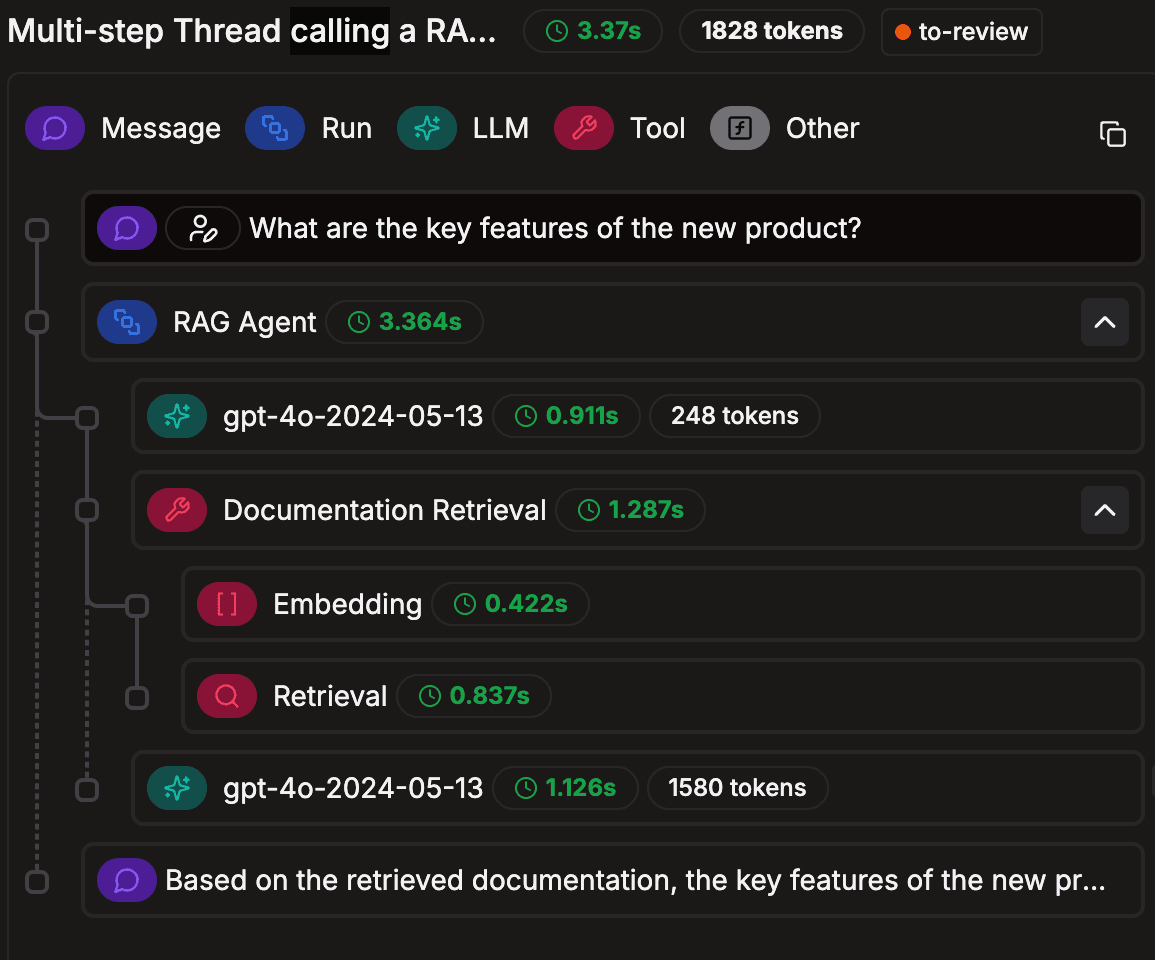
Logs & Traces
Log LLM calls, agent runs and conversations to debug, monitor and build datasets from real world data.
Logs & Traces
Log LLM calls, agent runs and conversations to debug, monitor and build datasets from real world data.
Logs & Traces
Log LLM calls, agent runs and conversations to debug, monitor and build datasets from real world data.
Logs & Traces
Log LLM calls, agent runs and conversations to debug, monitor and build datasets from real world data.
Playground
Create and debug prompts in our state of the art prompt playground. Including templating, tool calling, structured output and custom models.
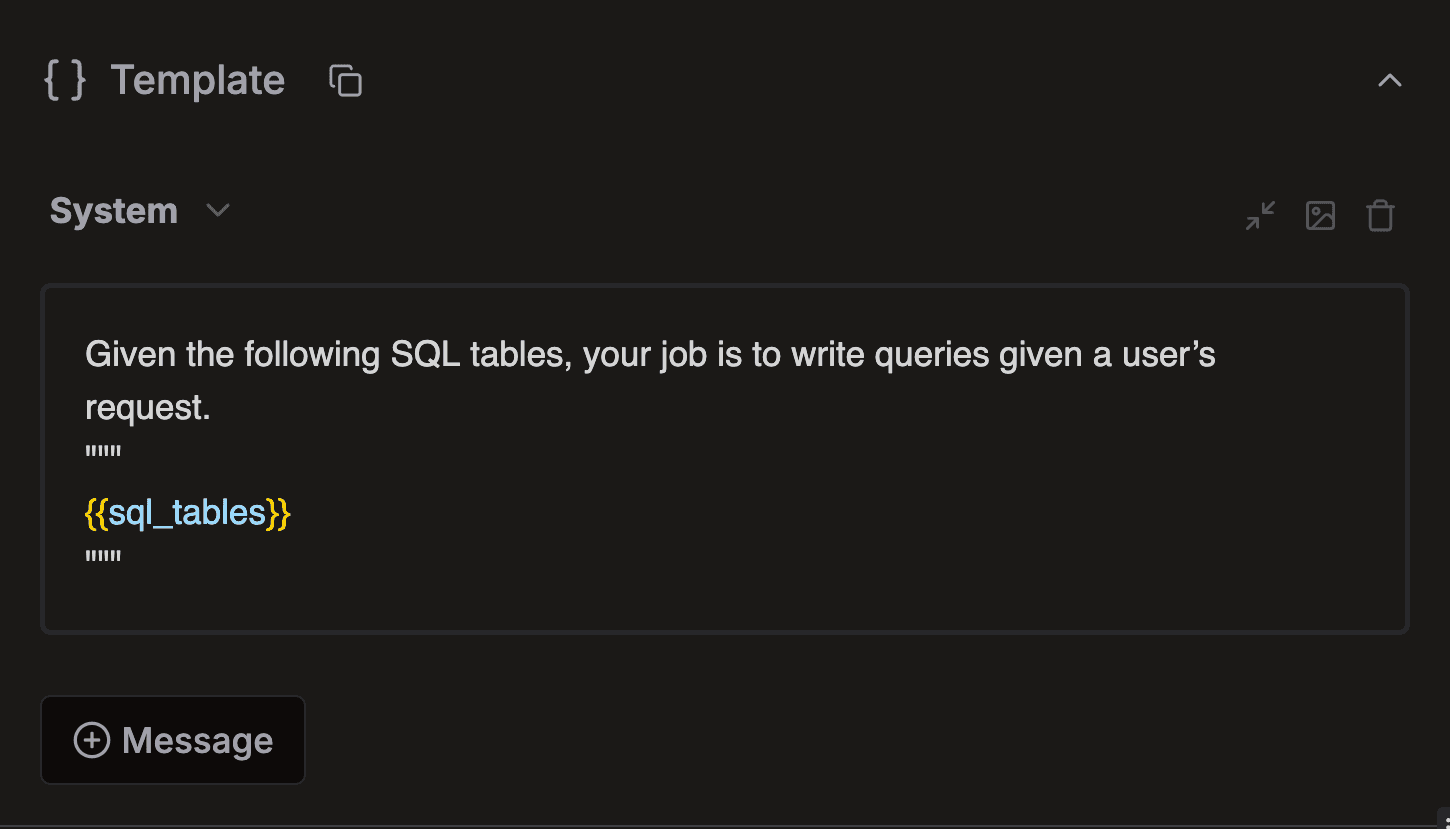
Playground
Create and debug prompts in our state of the art prompt playground. Including templating, tool calling, structured output and custom models.
Playground
Create and debug prompts in our state of the art prompt playground. Including templating, tool calling, structured output and custom models.
Playground
Create and debug prompts in our state of the art prompt playground. Including templating, tool calling, structured output and custom models.
Monitoring
Detect failure cases in production by logging & evaluating LLM calls & agent runs. Improve your LLM system from production logs. Track volume, cost, latency in a single dashboard.
Recommended time
to tweet
Monitoring
Detect failure cases in production by logging & evaluating LLM calls & agent runs. Improve your LLM system from production logs. Track volume, cost, latency in a single dashboard.
Recommended time
to tweet
Monitoring
Detect failure cases in production by logging & evaluating LLM calls & agent runs. Improve your LLM system from production logs. Track volume, cost, latency in a single dashboard.
Recommended time
to tweet
Monitoring
Detect failure cases in production by logging & evaluating LLM calls & agent runs. Improve your LLM system from production logs. Track volume, cost, latency in a single dashboard.
Recommended time
to tweet
Dataset
Manage your data in one place. Prevent data drifting by leveraging staging/prod logs.
Dataset
Manage your data in one place. Prevent data drifting by leveraging staging/prod logs.
Dataset
Manage your data in one place. Prevent data drifting by leveraging staging/prod logs.
Dataset
Manage your data in one place. Prevent data drifting by leveraging staging/prod logs.
Experiments
Create experiments against datasets on Literal AI or from your code. Iterate efficiently while avoiding regressions.
Experiments
Create experiments against datasets on Literal AI or from your code. Iterate efficiently while avoiding regressions.
Experiments
Create experiments against datasets on Literal AI or from your code. Iterate efficiently while avoiding regressions.
Experiments
Create experiments against datasets on Literal AI or from your code. Iterate efficiently while avoiding regressions.
Make it more creative
Evaluation
Evaluation is key to enable continuous deployment of LLM-based applications. Score a generation, an agent run or a conversation thread directly from your code or on Literal AI.
1
0.7
0.3
0
Answer Relevancy
5.1%
Make it more creative
Evaluation
Evaluation is key to enable continuous deployment of LLM-based applications. Score a generation, an agent run or a conversation thread directly from your code or on Literal AI.
1
0.7
0.3
0
Answer Relevancy
5.1%
Make it more creative
Evaluation
Evaluation is key to enable continuous deployment of LLM-based applications. Score a generation, an agent run or a conversation thread directly from your code or on Literal AI.
1
0.7
0.3
0
Answer Relevancy
5.1%
Make it more creative
Evaluation
Evaluation is key to enable continuous deployment of LLM-based applications. Score a generation, an agent run or a conversation thread directly from your code or on Literal AI.
1
0.7
0.3
0
Answer Relevancy
5.1%
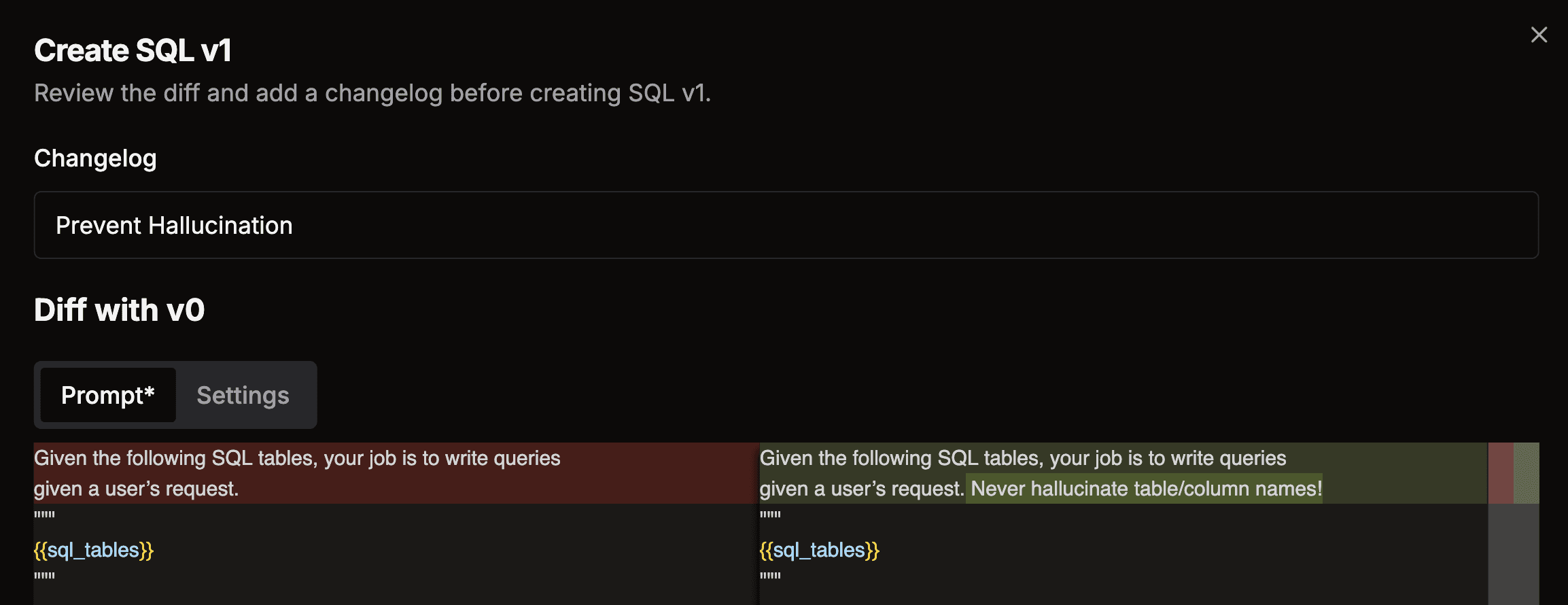
A
B
Prompt Management
Version, deploy and A/B test prompts collaboratively.
A
B
Prompt Management
Version, deploy and A/B test prompts collaboratively.
A
B
Prompt Management
Version, deploy and A/B test prompts collaboratively.
A
B
Prompt Management
Version, deploy and A/B test prompts collaboratively.
Human Review
Leverage user feedback and SME
knowledge to annotate data and improve datasets over time.
Human Review
Leverage user feedback and SME
knowledge to annotate data and improve datasets over time.
Human Review
Leverage user feedback and SME
knowledge to annotate data and improve datasets over time.
Human Review
Leverage user feedback and SME
knowledge to annotate data and improve datasets over time.












Engineers use Literal AI
Software Engineers, AI Engineers and Product teams leverage Literal AI to build LLM products.

Managing and understanding the performance of our chatbot is crucial. Literal has been an invaluable tool in this process. It has allowed us to log every conversation, collect user feedback, and leverage analytics to gain a deeper understanding of our chatbot's usage.

Managing and understanding the performance of our chatbot is crucial. Literal has been an invaluable tool in this process. It has allowed us to log every conversation, collect user feedback, and leverage analytics to gain a deeper understanding of our chatbot's usage.
Managing and understanding the performance of our chatbot is crucial. Literal has been an invaluable tool in this process. It has allowed us to log every conversation, collect user feedback, and leverage analytics to gain a deeper understanding of our chatbot's usage.
Managing and understanding the performance of our chatbot is crucial. Literal has been an invaluable tool in this process. It has allowed us to log every conversation, collect user feedback, and leverage analytics to gain a deeper understanding of our chatbot's usage.

Developing and monitoring all of our GenAI projects is a critical part of my role. Literal has been an absolute game-changer. It not only allows us to track the Chain of Thought of our agents/chains but also enables prompt collaboration with different teams.

Developing and monitoring all of our GenAI projects is a critical part of my role. Literal has been an absolute game-changer. It not only allows us to track the Chain of Thought of our agents/chains but also enables prompt collaboration with different teams.
Developing and monitoring all of our GenAI projects is a critical part of my role. Literal has been an absolute game-changer. It not only allows us to track the Chain of Thought of our agents/chains but also enables prompt collaboration with different teams.
Developing and monitoring all of our GenAI projects is a critical part of my role. Literal has been an absolute game-changer. It not only allows us to track the Chain of Thought of our agents/chains but also enables prompt collaboration with different teams.

Building an effective chatbot for Evertz's internal operations was a daunting task but working with Literal has made the process significantly easier. It has allowed us to analyze each step of our users interactions and to more quickly converge on the desired behaviour.

Building an effective chatbot for Evertz's internal operations was a daunting task but working with Literal has made the process significantly easier. It has allowed us to analyze each step of our users interactions and to more quickly converge on the desired behaviour.
Building an effective chatbot for Evertz's internal operations was a daunting task but working with Literal has made the process significantly easier. It has allowed us to analyze each step of our users interactions and to more quickly converge on the desired behaviour.
Building an effective chatbot for Evertz's internal operations was a daunting task but working with Literal has made the process significantly easier. It has allowed us to analyze each step of our users interactions and to more quickly converge on the desired behaviour.
built with security in mind
Enterprise Ready


Built by the team behind Chainlit
Literal AI is built by the team behind Chainlit.
Chainlit is an open-source Python framework to build Conversational AI applications used by over 80k developers monthly, and countless application users.
Ship AI with confidence
Gain visibility on your AI application
Create an account instantly to get started or contact us to self host Literal AI for your business.
Ship AI with confidence
Gain visibility on your AI application
Create an account instantly to get started or contact us to self host Literal AI for your business.
Ship AI with confidence
Gain visibility on your AI application
Create an account instantly to get started or contact us to self host Literal AI for your business.
Ship AI with confidence
Gain visibility on your AI application
Create an account instantly to get started or contact us to self host Literal AI for your business.