
In Part 1, we’ve laid out the building blocks of a vanilla RAG. RAG has evolved significantly since its introduction with dynamic architectures improving the retrieval performance. With these advanced strategies, it is even more important to observe the intermediate steps and evaluate RAG applications thoroughly. A simplified graph is as follows:
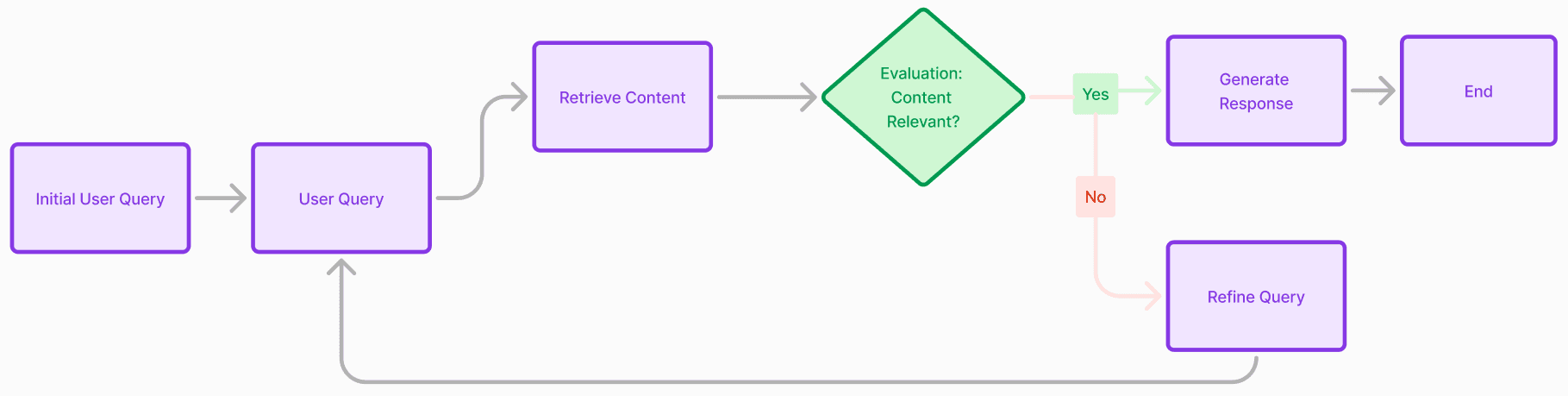
1. Adaptive RAG, Self-RAG, Corrective RAG
RAG techniques are fixed cognitive architectures with query and reflective nodes. The main idea of these techniques is to refine RAG with reflective nodes that assess is the relevancy of retrieved documents, and optionally perform other refined retrieve steps - either by rephrasing or by using a web search.
Papers: https://arxiv.org/abs/2401.15884, https://arxiv.org/abs/2403.14403, https://arxiv.org/abs/2310.11511
2. GraphRAG
GraphRAG incorporates structured knowledge graphs into the RAG framework, employing graph-based retrieval and relationship-aware generation. This technique enhances multi-hop reasoning and contextual understanding, leading to improved performance on complex tasks and better handling of relational information. Graph structures also excel at answering questions that relate to the overall knowledge base, such as “How many films are categorized as comedies?”
However, GraphRAG requires high-quality knowledge graphs and introduces increased computational complexity. It also necessitates the development of efficient graph update techniques to maintain relevance.
Check out Microsoft's work on Graph RAG: https://github.com/microsoft/graphrag and https://microsoft.github.io/graphrag/
and LlamaIndex: https://docs.llamaindex.ai/en/stable/module_guides/indexing/lpg_index_guide/
3. Agentic RAG
Agentic RAG leverages the tool calling and reasoning abilities of LLMs to have self-reflection and iterative refinement baked into the process. In this approach, the language model evaluates its own outputs and decides whether to retrieve additional information. This self-assessment mechanism improves output consistency and reduces hallucinations, potentially leading to higher quality results. The trade-off, however, is an increase in computational cost due to using one bigger LLM, instead of smaller ones (cf subpart 1).
Example: How to implement Agentic RAG
This simple agentic RAG implementation contains:
Multi-hop reasoning and retrieval
Rephrasing
Parallel tool calling for parallel retrieval
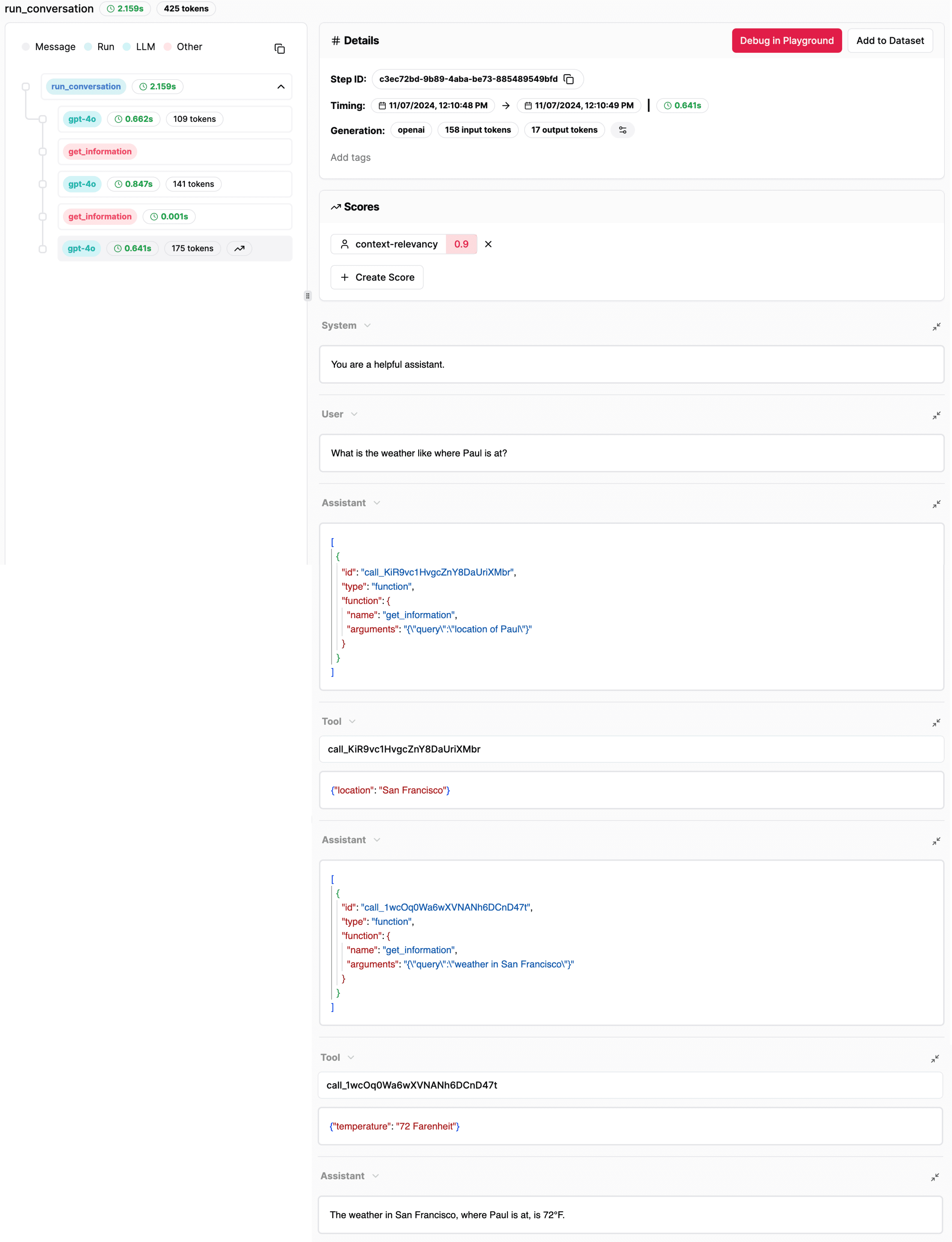
The user asked for the weather where Paul is located.
The RAG agent makes a tool call to retrieve Paul's location, which is San Francisco.
With Paul's location known, the RAG agent chose to make another function call to get the current weather in San Francisco, which is 72°F.
The final response was then generated.
The process end-to-end is: LLM call => Tool call (get Paul's location) => LLM call => Tool call (get SF's weather) => LLM call.
Pros
Dynamic Retrieval: Adapts to complex queries by breaking them into subtasks.
Improved Accuracy: Builds context progressively, reducing hallucinations.
Flexibility: Adjusts retrieval strategy based on initial results.
Transparency: Allows tracking of the system's reasoning process.
Cons
Increased Latency: Multiple retrieval steps can slow response times.
Higher Costs: More API calls and processing increase operational expenses.
Potential Issues: Risk of loops, error propagation, and caching difficulties.
Conclusion & Literal AI
As RAG evolves towards more agentic systems, incorporating self-reflection and adaptive decision-making, the need for robust evaluation becomes critical. Literal AI offers a solution to assess these advanced RAG applications, ensuring their effectiveness and reliability. By evaluating complex, agentic RAG systems, Literal AI helps developers and product managers manage prompts, track experiments, optimize performance and build trustworthy AI assistants and applications. Here is a live example of the observability feature.
You can start either in Python or TypeScript and leverage the multiple integrations (OpenAI, LangChain, LlamaIndex, etc.) we have. It's easy to get started in no more than two lines of code: start here now!