

Hi from Literal AI 👋
We're excited to bring you new features and improvements!
Check out the following video by Willy on Evaluation and Experiments.
Scorers
The concept of "Scorer" has been added. With Scorers, you can run experiments directly on the platform and evaluate new logs in near real-time.
Scorers natively support structured output, which ensures consistent and efficient evaluations.
Go ahead and define your own LLM-as-a-Judge Scorers!

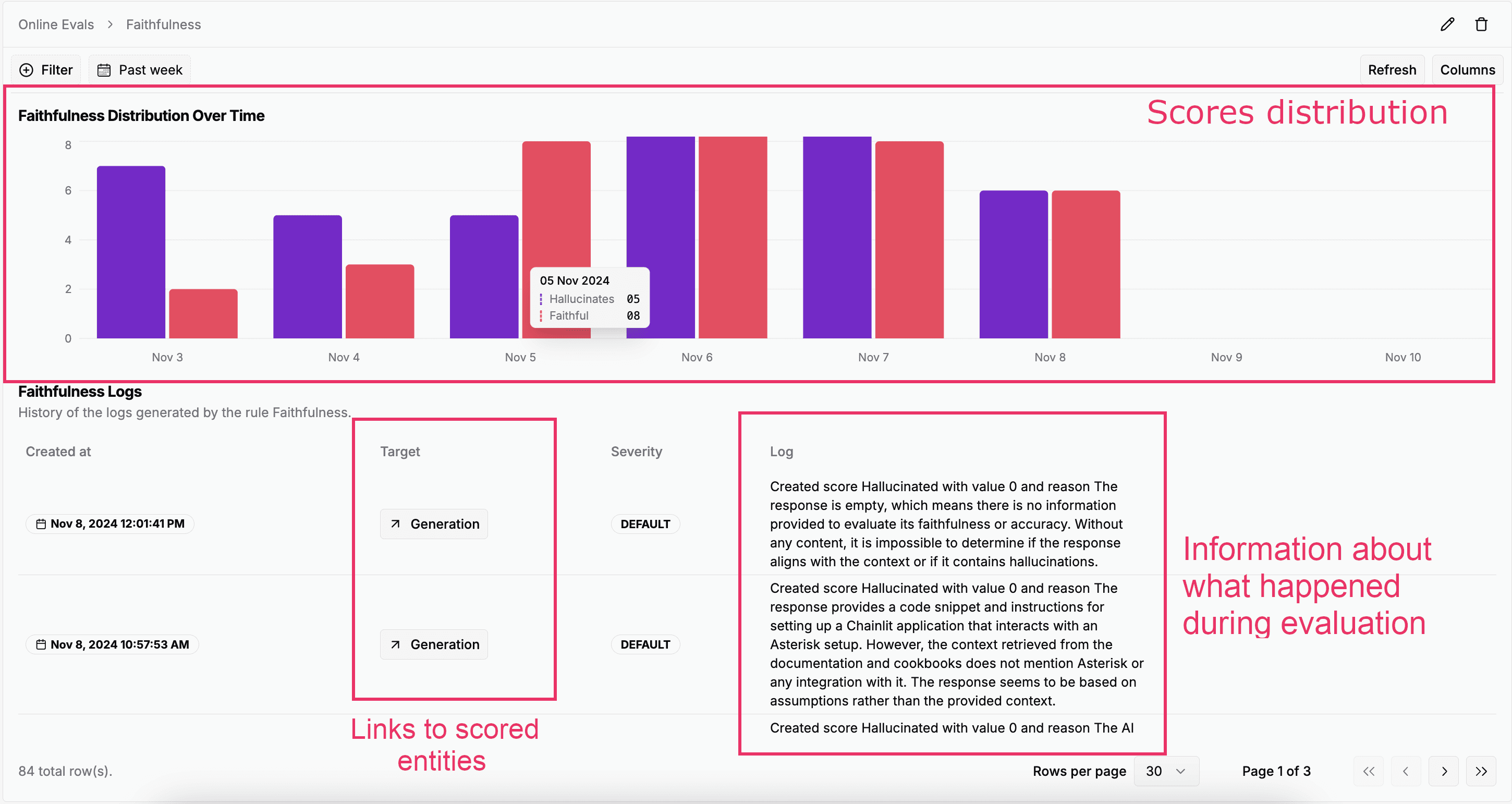
Online Evaluations
Online Evaluations have been improved to work with Scorers. You can reuse the same Scorers for experimentation and monitoring using Online Evaluation!
Experiments
You can now run experiments directly from the Prompt Playground to test changes against a dataset before saving them!
Spoiler: It uses Scorers!

Additionally, the experiments table is now sortable by score, and the experiment detail page UX has been reworked. You can benefit from these improvements whether you run your experiments directly on Literal AI or from your code.
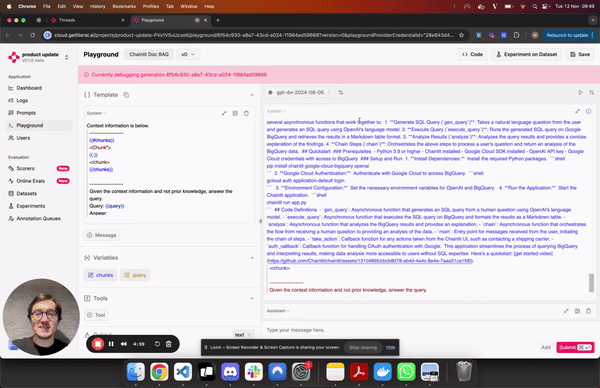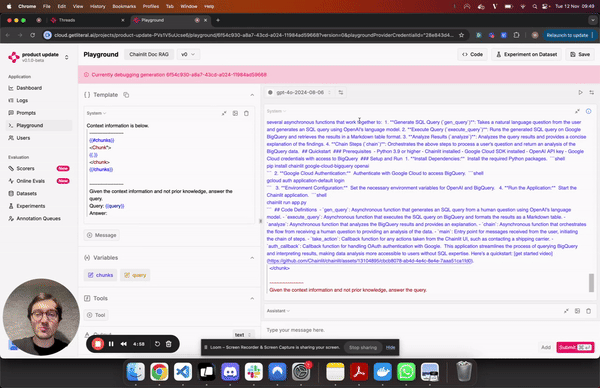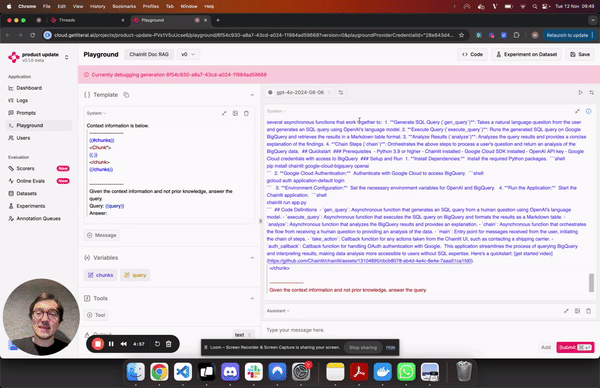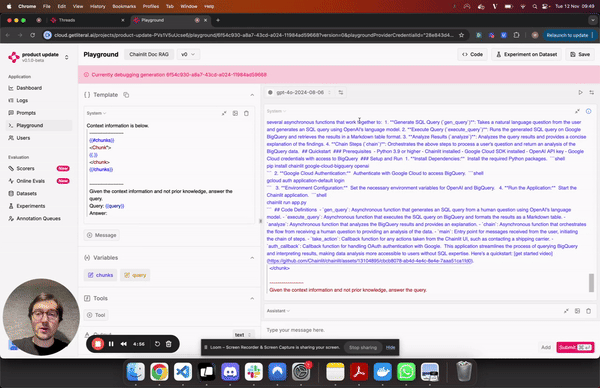
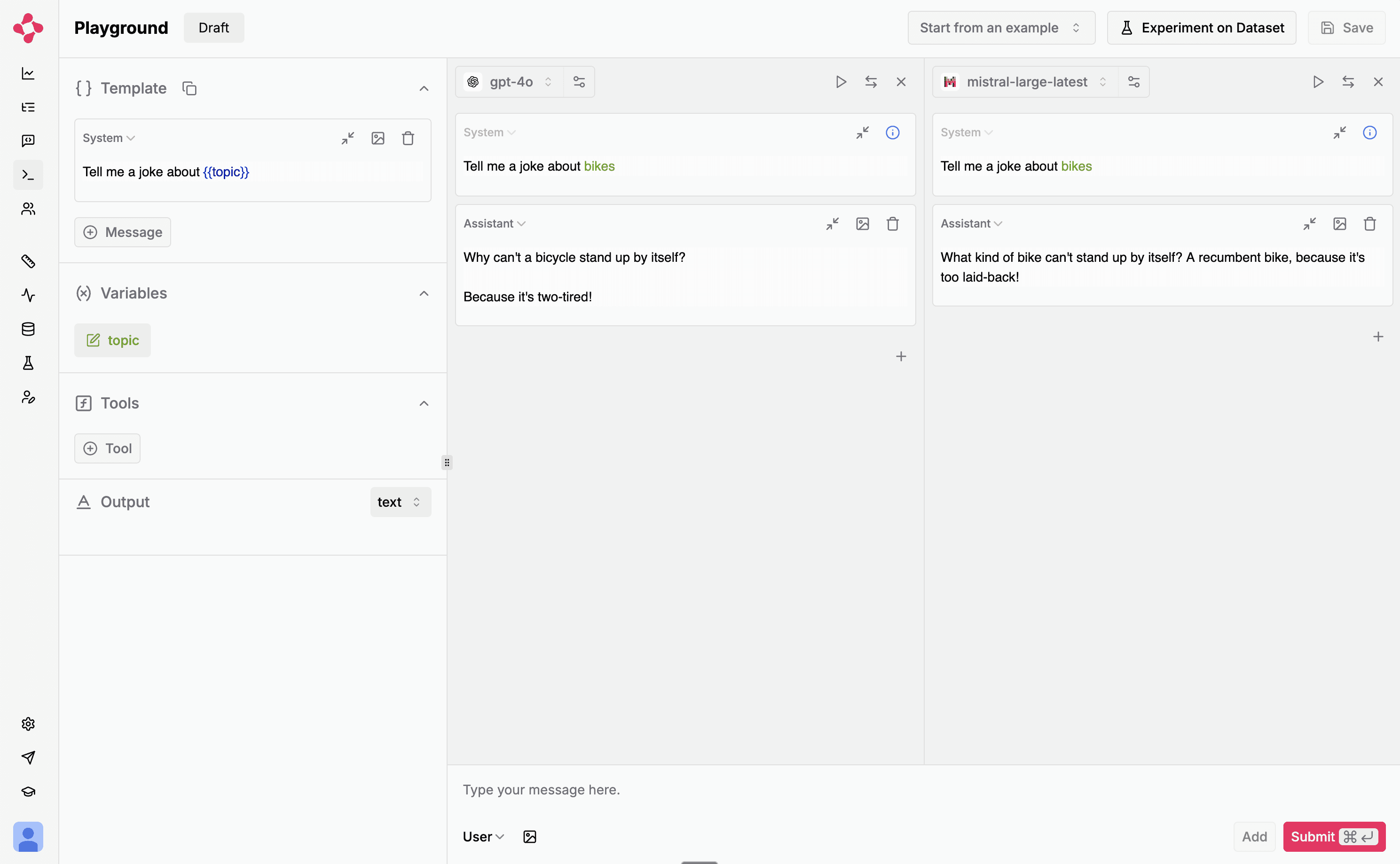
Playground
You can now vibe-check and compare LLMs and providers in a side-by-side view. Additionally, the playground and the prompt management system now support structured output.
Improvements
Dataset items are now editable.
The LLM credential UX has been reworked and is much simpler.
The LangGraph integration has been greatly improved.
Support for LiteLLM SDK and proxy.
You can now tag prompts.
Chainlit
In the news
Evaluate RAG pipeline with LlamaIndex, Ragas and Literal AI - Part 1: Link
Nvidia Sales agent with LlamaIndex and Chainlit: Link
📗 Check out the full release notes.
Give these a try and let us know what you think by dropping a reply to this email!
Thank you!
The Literal AI team